At the end of part 1 we had distances between trail junctions but with a couple issues:
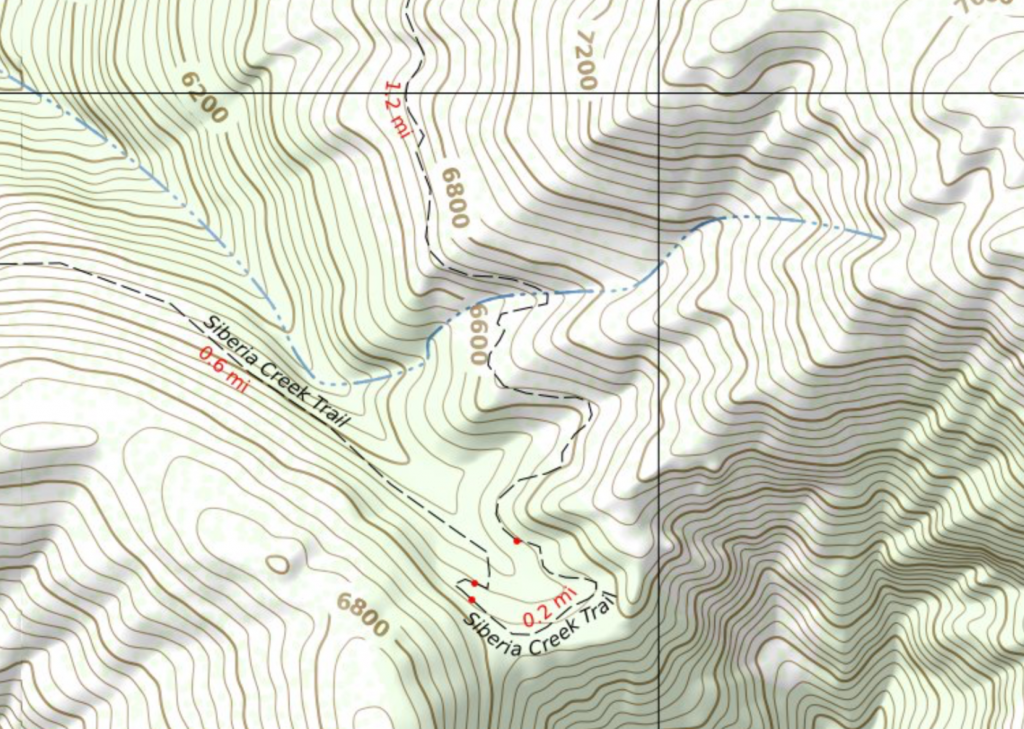
If mapper(s) had split a trail for any reason then our distances were between splits. Even if there was nothing on the ground notable at the split to for the hiker to recognize. Maybe one mapper used surface=ground and another mapper used surface=dirt.
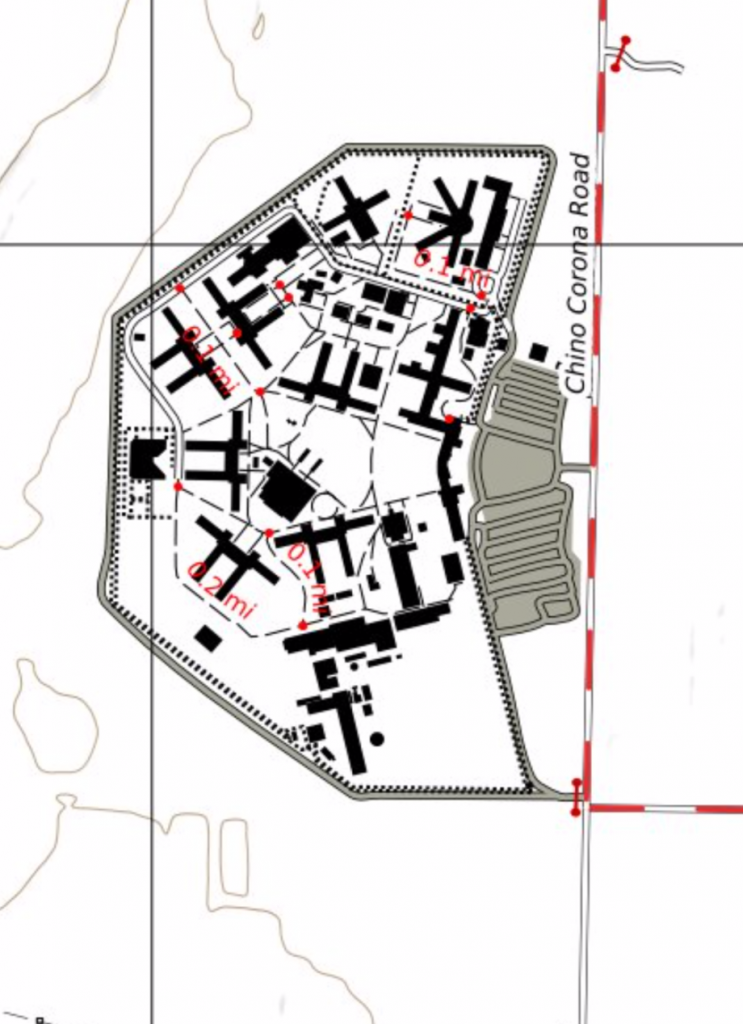
And we had a case of measles where there were walkways in suburban parks and office complexes.
This is one of those cases where we got about 90% of the goal with 10% of the work. Now it is time to dig into the 90% effort to get this correct. Or at least as correct as I think it can be.
To be fair, much of the 90% work value is due to my environment:
- Modifying old scripts that have evolved over several years. Each iteration based on my limited understanding of OSM and Postgis tools at the time.
- Using older OSM tools with some limitations that were not immediately apparent.
- Not being an expert on Postgis and finding that a number of Postgis functions don’t seem to work or are not available on my server.
- Using a server with limited RAM to build the maps.
- Slow iterations on each try due to slow building of map databases and slow map generation (see using a limited server above).
When can trail ways be combined?
The fix to extraneous splits in a trail is to “heal the edges of” or “clean the phantom nodes from” our routing graph. It seems both terms are used and you get different DuckDuckGo results depending which you search on. I will call it “healing”.
We only want to heal ways that are similar enough. If a paved walkway leads to an unpaved hiking trail there is a noticeable change in character and we don’t want to “heal” (combine) the two ways. But if there is a short informal bridge we probably do want to “heal” it away. So our goal is to heal all “hiking trails” to each other but not “heal” a “hiking trail” to a “walkway” or any other type of highway.
What the heck is a “hiking trail”?
The first problem is how to determine if a way is a “hiking trail” or not. A clear definition of what is or is not a “hiking trail” is hard. Apparently it is one of those “I know it when I see it” things.
The wiki is, in my opinion, unhelpful on this. Images of what I would call a “hiking trail” are shown for both “footway” and “path” with the determination seeming to be a “footway” is primarily for pedestrian traffic while a “path” is for combined traffic.
In my area, most trails are for general use and open for pedestrians, bicyclists and equestrians so highway=path might be correct and most mappers use “path”. But some mappers have decided that the primary use is for pedestrians, maybe because bicycle and horse traffic is much less, and have decided to use highway=footway. This seems to be region dependent perhaps driven by the local default restrictions on horses and/or bicycles.
And in either case, there is no clear description of how to distinguish a rural “footway”/“path” suitable for hiking from a urban/suburban one suitable for pushing a baby stroller or use with a wheelchair.
I had been cheating on this: Rendering both footway and path the same. That was the reason that some office complexes had the red dot measles appearance when I applied trail distance graphics to them. To distinguish a smooth, hard surfaced urban/suburban walkway from a rough, unpaved hiking trail you need to look at other tags.
After a couple of tries I ended up creating a script that reads a .osm file from stdin and writes a modified .osm file to stdout. Since the .osm files created by osmconvert and osmium are pretty stylized, I did not have to actually parse the XML or hold the whole file in memory. Simply copying lines from input to output and using tools like grep and sed I could collect the tags for each way and then for ways with a “highway” tag look at all the tags and make a decision of “trail” or “not trail”. In either case a single line written to the output adds a new unique hiking_trail=yes|no tag each highway=* way object.
The script looks at the tags and based on the tag name, the tag values and sometimes a combination of tags creates a score. After looking at all tags the score is checked and if a threshold is passed the path or footway is categorized as a trail or not. The tags evaluated include:
- access
- bicycle
- cycleway:surface
- est_width
- foot
- footway
- footway:surface
- highway
- horse
- horse_scale
- informal
- mtb:scale
- name
- sac_scale
- smoothness
- surface
- trail_visibility
- wheelchair
- width
Sometimes the mere presence of a tag, like trail_visibility, is all that is needed. In other cases, like surface, the actual values need to be considered.
I am reminded a bit about the early efforts to separate spam from email as the logic is similar. I am helped in this case because mappers are not actively trying to fool my filter: They are simply as confused as I am.
Having trails identified can be useful for rendering too, so I decided to use this in my overall database. When I collect my various extract files into one big file for loading my database I add the unique trail identification result:
osmconvert *.o5m --out-osm | utils/identifyTrails | osmium cat --input-format=osm --overwrite --output=planet.pbf
Another cheat to be fixed
On my first cut I loaded only things that might be trails (“footway” and “path”) into my routing (“nodes” and “edges”) database. But I don’t want to heal trail edges where they cross highways. In fact, if a trail crosses an access road I want to split the trail as that location is or could be an informal trail access point.
To do this I need to load all the various highway=* ways into the routing database and then only heal the trails. With the script described above I can create a highways only file:
osmium tags-filter planet.pbf w/highway --overwrite --output=roads_only.pbf
But everything is too big
This is where things started to go pear shaped. When I was only processing highway=path and highway=footway with osm2pgrouting everything worked fine. But for even just one state extract with all highways osm2pgrouting started acting up. There were two issues:
- Processing time was incredibly long. In fact I never completed the larger extracts.
- osm2pgrouting silently fails when it runs out of memory. That is, osm2pgrouting is itself was silent but postgresql would start complaining about data after last expected column when osm2pgrouting was having difficulties. The difficulties seemed be related to how much memory osm2pgrouting had to work with.
I tried various things like increasing the virtual memory available. But the only thing that worked was using an extract that covered only a very small area. It seems others are able to use osm2pgrouting on large area extracts so I assume there is something about how I was provisioning virtual memory (VM). Or maybe it somehow needs real memory and paging VM breaks it.
Using a filter in osmconvert to create an extract the size of my target map seemed to work. But I found that for the “wilderness” parks surrounded by urban areas there were odd trail distances in the middle of the map without a trail near by. Investigating, it seemed that osmconvert was including data from places nearly 100 miles away! Fortunately osmium can also be used to create an extract and it seems to work correctly. It took me much too long to stop trying things with osmconvert and try it with osmium.
But we still need to heal the edges
There are some standard solutions for healing network edges but when working with a full extract (before figuring out osm2pgrouting was messing up) it was very slow, so I ended up hacking a script that only attempted to heal trails.
First step is to identify potential nodes to heal (remove). All the nodes that have only two edges pretty easily are easy to find:
SELECT id, osm_id
FROM (SELECT id, route_ways_vertices_pgr.osm_id AS osm_id, count(id)
FROM route_ways_vertices_pgr, route_ways
WHERE (id=target or id=source)
GROUP BY id) AS FOO
WHERE count=2;
And you can get all the nodes that have only two hiking trail edges. In my case, I mapped the hiking_trail value into the edge priority:
SELECT id, osm_id
FROM (SELECT id, route_ways_vertices_pgr.osm_id AS osm_id, count(id)
FROM route_ways_vertices_pgr, route_ways
WHERE (priority=1) AND (id=target or id=source)
GROUP BY id) AS FOO
WHERE count=2;
A candidate for removal is a node that has two and only two edges where both edges are hiking trails. Our first query gets the “two and only two” edges. The second query gets “only two hiking path edges but there might be other non-hiking path edges”. An intersection of those two results gets us pretty close to what we want:
SELECT id, osm_id
FROM (SELECT id, route_ways_vertices_pgr.osm_id AS osm_id, count(id)
FROM route_ways_vertices_pgr, route_ways
WHERE (id=target or id=source)
GROUP BY id) AS FOO
WHERE count=2
INTERSECT
SELECT id, osm_id
FROM (SELECT id, route_ways_vertices_pgr.osm_id AS osm_id, count(id)
FROM route_ways_vertices_pgr, route_ways
WHERE (priority=1) AND (id=target or id=source)
GROUP BY id) AS FOO
WHERE count=2;
Not all candidate nodes can be removed. Consider the following trail junction.

There are two and only two ways that come together at that junction and they are both hiking trails. So the junction node is included in our candidates to remove. But when you perform a ST_LineMerge() operation on the edges you end up with a ST_MultiLineString rather than a ST_LineString.
Once everything is checked then the edges associated with the node are merged into one record (update one edge and remove the other) and the node is removed. There is a bunch of bookkeeping is updated it the way that is updated (way length in meters, source node ID, destination node ID, etc.).
My Postgresql/Postgis skills are not sufficient to allow me to do all checking and bookkeeping update logic within a stored procedure so all this got implemented in a shell script and is not particularly fast to run.
Between slow healing on large databases and the issues with osm2pgrouting not working well with large data sets, I ended up creating the routing database for only the area of the map I am generating:
osmium extract -b $west,$south,$east,$north osm/roads_only.pbf --overwrite -o osm/extract.osm osm2pgrouting --f osm/extract.osm --prefix route_ --conf osm/pgrouting_mapconfig.xml --username me --dbname osm --clean utils/merge_edges
The results
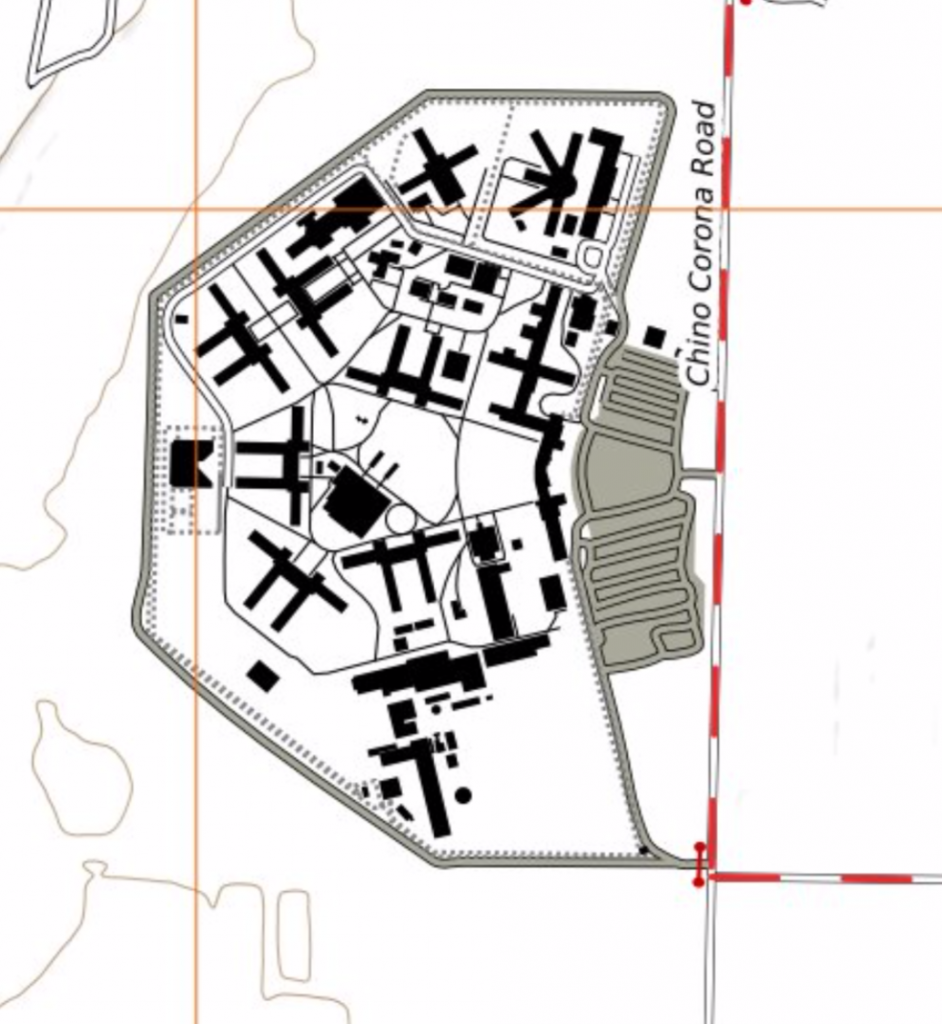
Our office park measles are gone.
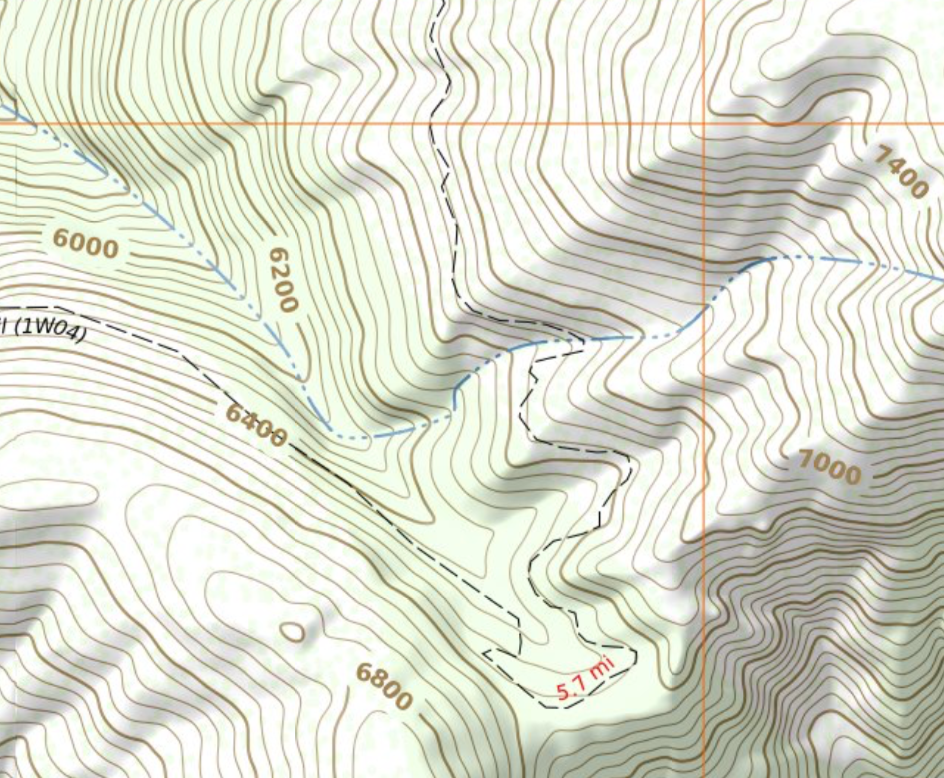
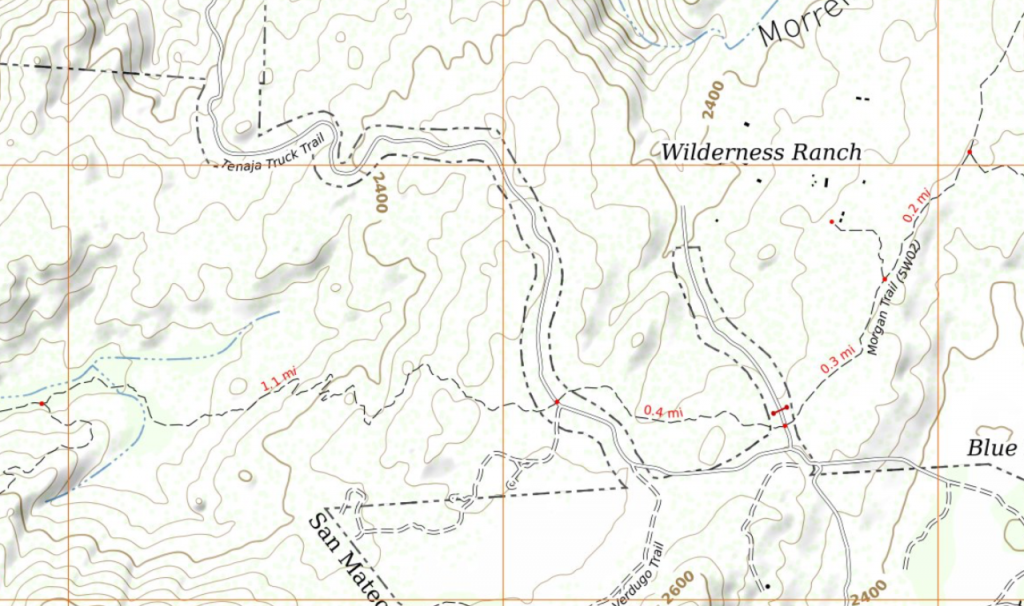
Our trails have been healed.
With different rendering for urban/suburban walkways and rural hiking trails it is easier to see when one unexpectedly shows up in an odd place. That allows me to examine the OSM data for it and update my identification logic.